Consideram-se dados de investigação todos os elementos, independentemente do seu formato ou suporte, que sejam recolhidos, registados, gerados ou tratados no âmbito de um projeto de investigação científica, e que sejam essenciais para a validação dos resultados, a formulação de conclusões e, em geral, a produção de novo conhecimento.
Podem abranger diversas tipologias, tais como: Dados quantitativos (p.ex. resultados de medições, estatísticas, bases de dados numéricas); Dados qualitativos (p.ex. transcrições de entrevistas, respostas a questionários, notas de campo, textos); Dados experimentais (p.ex. leituras de instrumentos, imagens, sequências genómicas); Dados computacionais (p.ex. modelos, algoritmos, simulações, código-fonte).
A gestão dos dados de investigação, numa perspetiva de Ciência Aberta, e em consonância com os princípios FAIR (Findable, Accessible, Interoperable, Reusable) refere-se ao processo de organização, armazenamento, partilha e preservação responsável dos dados gerados na investigação científica visando a sua disponibilização pública e gratuita, com vista à sua reutilização por investigadores, decisores e cidadãos. Aplica-se a todas as etapas de vida útil dos dados, desde a sua recolha até ao armazenamento final, garantindo a sua estruturação, documentação e proteção. Procura-se garantir a transparência dos processos de produção do conhecimento, a reprodutibilidade dos dados e a colaboração entre os investigadores, assegurando boas práticas e contribuindo para a qualidade e integridade da investigação.
Os princípios FAIR constituem um conjunto de diretrizes orientadoras destinadas a promover a gestão responsável e eficiente dos dados de investigação. Não se configuram como normas ou requisitos formais, mas como referenciais de boas práticas que descrevem as caraterísticas essenciais para maximizar a reutilização dos dados. Entre estas, destacam-se a descrição rigorosa, a utilização de metadados normalizados e a citação adequada dos conjuntos de dados. Além disso, os princípios FAIR enfatizam a capacidade das máquinas de localizar, aceder e utilizar automaticamente dados ou outros objetos digitais, ao mesmo tempo que favorecem a sua reutilização por utilizadores humanos.
Cada letra do acrónimo FAIR corresponde a um conjunto de 15 princípios.
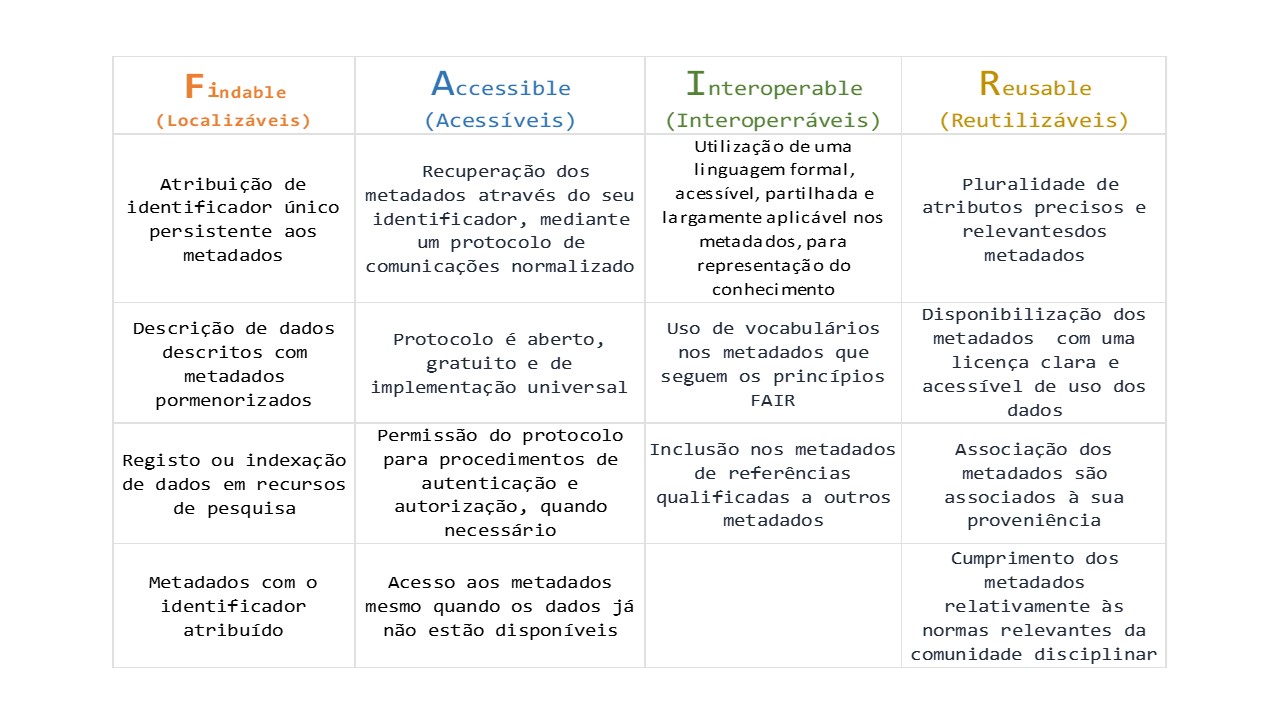
Os dados podem ser recuperados ou produzidos através de uma ampla gama de formatos: conjunto de dados digitais, bases de dados, registos de texto, áudio ou vídeo, resultados de questionários, entrevistas, observações, simulações, resultados de experiências, medições, simulações, tabelas, observações resultantes de trabalhos de campo, artefactos, fotografias, contribuições em redes sociais, estatísticas.
Podem ser considerados dados de investigação:
- Dados em bruto: aqueles que são capturados através de instrumentos e sensores, como telescópios, smartphones e satélites.
- Visualizações, modelos e algoritmos: os investigadores também produzem recursos digitais tais como modelos e algoritmos para auxiliar a analisar, visualizar e apresentar dados em bruto de forma significativa.
- Imagens, áudio e ficheiros de vídeo: imagens digitais também são consideradas como dados, assim como quaisquer ficheiros de vídeo ou áudio capturados no decorrer de uma investigação, tais como as entrevistas gravadas.
- Qualquer coisa! essencialmente, dados de investigação pode ser tudo aquilo que os investigadores produzam ou trabalhem durante o decurso da sua investigação.
Dados abertos
Dados de investigação abertos são dados que podem ser livremente acedidos, reutilizados, remisturados e redistribuídos, para efeitos de investigação académica e ensino e outros fins.
Idealmente, os dados abertos não têm restrições de reutilização ou redistribuição, e têm licenças apropriadas para tal. Em casos excecionais, por exemplo para proteção de identidade de pessoas, são estabelecidas restrições especiais ou limitadas de acesso. Partilhar abertamente os dados expõe-nos à inspeção, o que constitui a base para a verificação e reprodutibilidade da investigação, e abre o caminho para a mais ampla colaboração. No máximo, os dados abertos podem estar sujeitos ao requisito de atribuição e partilha de modo igual.
Dataset
Conjunto de dados. Estes dados em conjunto são tratados como uma única unidade de informação.
Big data
Conjuntos de dados muito grandes ou complexos, com os quais os aplicativos de processamento de dados tradicionais ainda não conseguem lidar. Representam um desafio quanto ao seu armazenamento e tratamento. Os desafios colocados pelos Big Data incluem: análise, captura, curadoria, pesquisa, partilha, armazenamento, transferência e visualização, bem como informação sobre privacidade dos dados.
Podemos distinguir os tipos de dados de acordo com:
a) Grau de processamento:
- Em bruto: dados de investigação obtidos diretamente do processo de investigação, instrumento ou metodologia científica, sem que tenham sofrido qualquer processamento ou transformação (p. ex.: entrevista áudio/vídeo sem edição, dados gerados por um instrumento de medição sem que tenham sofrido processamento).
- Processados: dados resultantes da interpretação, processamento ou transformação de dados em bruto (p. ex.: entrevista áudio/vídeo após edição, dados gerados por um instrumento de medição após processamento ou aplicação de modelos estatísticos).
b) Proveniência (do ponto de vista do investigador):
- Primários: dados gerados pelo próprio, no decorrer da sua investigação;
- Secundários: dados disponíveis (abertos), reutilizados por outros que não os seus produtores. Estes dados, para serem usados, necessitam de ter documentação de contextualização associada.
c) Dimensão:
- Big data: dados (datasets) de grande dimensão, muitas vezes provenientes de instrumentos específicos;
- Long tail data: datasets de pequenas dimensões. Dada a sua natureza heterogénea, constituem um maior desafio em termos de planeamento, gestão, preservação e reutilização, devido à sua natureza heterogénea e singular.
d) Tipo de investigação desenvolvida:
- Dados de observação: capturados em tempo real, geralmente únicos e insubstituíveis (p. ex.: imagens cerebrais, dados de inquéritos);
- Dados experimentais: recolhidos a partir de equipamentos de laboratório, podendo ser reprodutíveis (p. ex.: cromatogramas, micro-ensaios);
- Dados de simulação: gerados a partir de modelos de teste, onde os modelos e metadados podem ser mais importantes do que os dados resultantes do modelo (p. ex.: modelos económicos e climáticos);
- Dados derivados ou compilados: resultam do processamento ou de combinação de dados em bruto, podendo ser reprodutíveis;
- Dados de referência ou canónicos (estáticos ou orgânicos): coleções de pequenos conjuntos de dados (revistos por pares), podendo ser publicados e curados (p. ex.: banco de dados de genes).